
Pragma Analytics Software Suite
Nous vous invitons à parcourir la suite de cette présentation afin de comprendre notre solution.
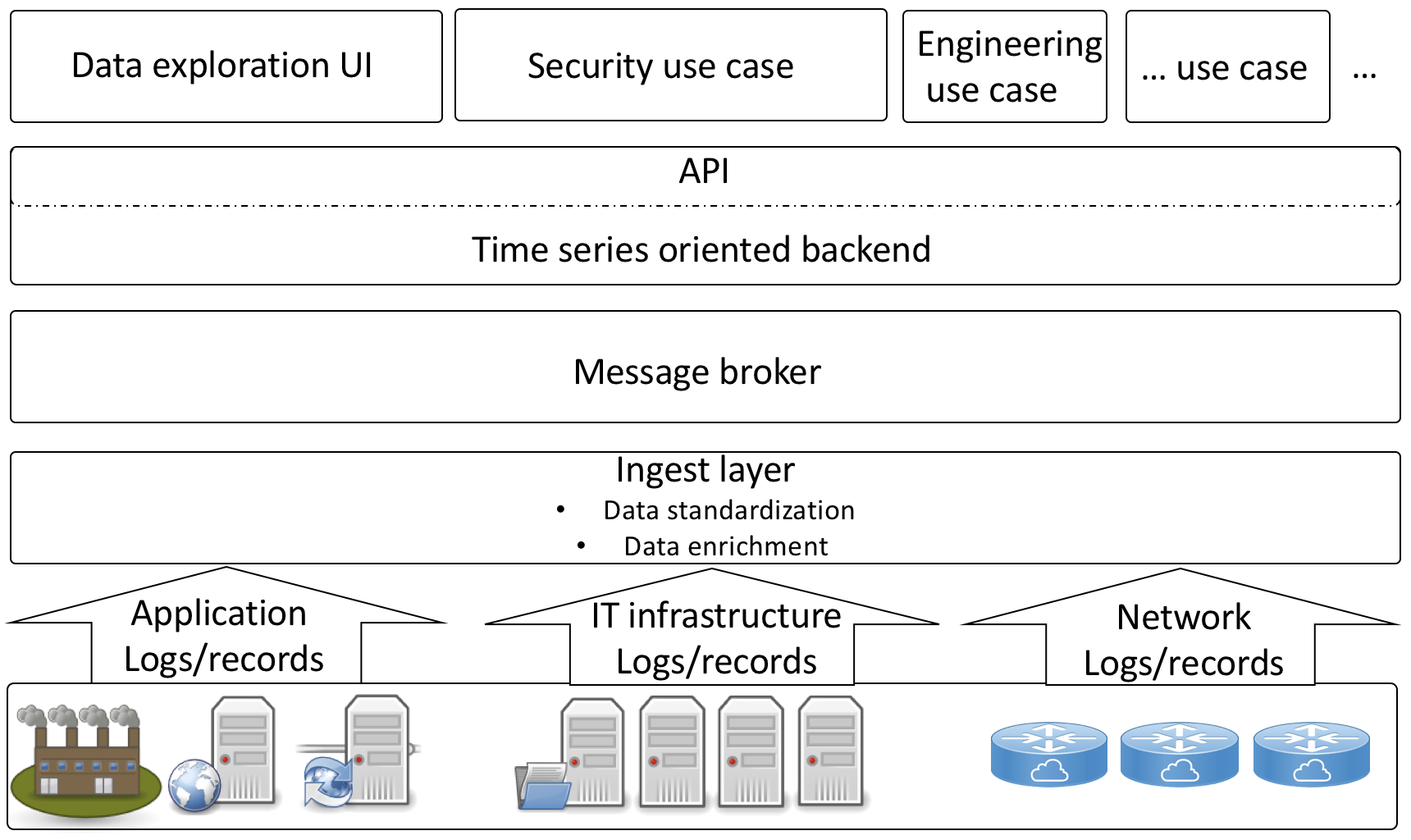
Pragma Analytics Software Suite Architecture
- La couche d’ingestion des données assure la mise en forme, l’enrichissement et la standardisation du format des données,
- Le message broker assure les échanges de donnée entre la couche d’ingestion et le backend,
- Le backend assure le stockage, la consultation et le niveau de résilience souhaité pour les données.
Enfin, s’appuyant sur l’API du backend, nous trouvons :
- des outils de consultation des données et d’organisation de dashboards,
- des cas d’usage de sécurité,
- d’engineering,
- d’optimisation de workflow métier.
Pour chacune de ces fonctions de référence, nous avons valider des logiciels que nous pouvons assembler afin de répondre à un cahier des charges. Notre expertise peut aussi vous être proposée afin de valider vos hypothèses de travail.
Ingest layer
Les modules que nous utilisons actuellement sont soit des modules open source comme PMACCT (donnée Netflow et sFlow), soit des modules développés par nos soins en golang (traitement SNMP, CDR Charging Data Records des réseaux voix)


Message broker et communication inter process
Afin d’assurer la communication entre les modules d’une même couche, nous privilégions l’utilisation de la librairie Zero MQ. Les données sont échangés en binaire ou via une standardisation simple de type message pack. L’utilisation du format JSON peut être source de problème de performance au moment sa serialisation / dé serialisation.
Pragma Innovation se positionne sur un segment bien spécifique du big data. Nous nous intéressons aux problématiques liées à l’analyse des événements ou la notion de temps est cruciale. Nous pouvons répondre à des besoins tel que les puits de logs, l’analyse des tickets de facturation, des tickets venant d’équipements réseaux ou de chaine de production.
Afin de répondre à ces besoins, nous pouvons utiliser deux types de backend suivant votre besoin: Druid mais aussi clickhouse.
Ces deux solutions sont assez proches l’une de l’autre. Toutes deux sont basées sur un modèle dit « columnar db » ou encore modèle OLAP . Druid permet une aggregation temporelle automatique que clickhouse ne permet pas. Clickhouse offre une flexibilté et une interface SQL que Druid ne permet pas toujours. Suivant vos cas d’usage spécifiques nous vous orienterons vers la meilleure solution pour vos besoins. Vous pouvez aussi consulter nos cas d’usage existants.
Nous ne saurions nous passer de l’utilisation de la très robuste base de donnée PostgreSQL qui sera en charge de traiter la consultation des meta-données de nos solutions big data. Ce type de base de données est aussi utilisée par le Frontend de la solution PASS.
Big data, la tarte à la crème ! Nous profitons de cette section pour préciser ce que big data veut dire pour Pragma Innovation. Nous sélectionnons nos solutions afin qu’elles soient évolutives horizontalement. Aussi, une solution big data doit avoir la possibilité d’être réduite à un seul et unique serveur avec quelques TB de données. Elle doit pouvoir évoluer jusqu’au PetaByte et accompagner nos clients dans leur croissance. Il est donc simple et peu coûteux d’évaluer la stack PASS.
Frontend et dashboards
Tout système de consultation de données se doit d’avoir une interface graphique qui soit à la fois simple d’utilisation et riche en fonctionnalités graphiques. Nous avons retenu l’open source Superset qui fut initialement développé par AirBnB puis repris récemment pour la fondation Apache.
Ce frontend dispose d’un driver vers un backend de type Druid mais il est aussi capable de s’interfacer avec tout système proposant une interface SQL. Ce frontend se connecte au data base SQL au travers de la librairie SQLAlchemy.
Superset utilise le framework Flask , Il utilise Javascript afin d’offrir de bonne performance graphique (REACT.JS) et utilise un large éventail des possibilités de la librairie D3.js. Nous recommandons l’utilisation de ce Frontend sur nos déploiements.
Si un outil existant doit être pris en compte, il sera possible d’envisager une intégration. A titre d’exemple, un outil graphique tel que Grafana dispose de plug-in pour nos backends.